
應用機器學習評估坡地崩塌發生的可能性
陳麒文 國立臺灣大學 地質科學系 助理教授
許大為 專案佐理研究員 國家災害防救科技中心
朱芳儀 專案佐理研究員 國家災害防救科技中心
前言
隨著全球暖化造成氣候變遷、極端降雨事件愈發頻繁,臺灣地質破碎且山地面積比例高,颱風及暴雨事件容易誘發土石流與崩塌等坡地災害。例如,拉斯克溪(荖濃溪支流)在莫拉克風災時,上游發生大量崩塌,多年來土石不斷向下移動,對勤和部落造成威脅,未來類似情形也可能會在臺灣任何地方發生。崩塌發生的因素眾多,例如:海拔、坡度、坡向、地形、地表濕度、降水量、地質條件等。這些因素亦可能互相影響,僅針對任意幾種因素進行評估較難準確預估崩塌潛勢。而機器學習方法能夠有效率的一併對這些因素進行訓練,得到的模型可用來評估未來發生坡地崩塌的可能性,作為氣候變遷下坡地災害風險之參考。
決策樹與隨機森林
機器學習(machine learning)中常見的演算法有貝氏分類器(Naïve Bayes classifier, NB)、K-近鄰演算法(k-Nearest Neighbor, kNN)、決策樹(Decision Tree, DT)、隨機森林(Random Forest, RF)、支援向量機(Support Vector Machine, SVM)等。其中的決策樹是一種用於數據挖掘與統計分析的機器學習模型,由節點(Nodes)和分支(Branches)組成,而葉節點(Leaf Node)即為該模型的預測結果[1]。決策樹可以用於處理分類(Classification)和迴歸(Regression)問題。決策樹的優點包括簡單易懂、對數據的前處理要求不高、計算量速度快、能夠處理非線性關係的數據。然而,決策樹有過度擬合(Overfitting)(無法很好的預測訓練集之外的數據)的問題。決策樹在每一次分離過程中選擇的特徵[註1]是基於某種準則,如信息增益(Information Gain)、增益比(Gain Ratio)、Gini不純度(Gini Impurity)來最大化子集的純度或最小化不確定性。隨著決策樹的深度增加,直到樣本無法繼續被分離或是達到設定的停止標準,每個終端節點(Leaf Node)皆代表一個預測結果,本案例的模型會根據所有崩塌與否的分類結果進行多數決作為整體模型的預測。
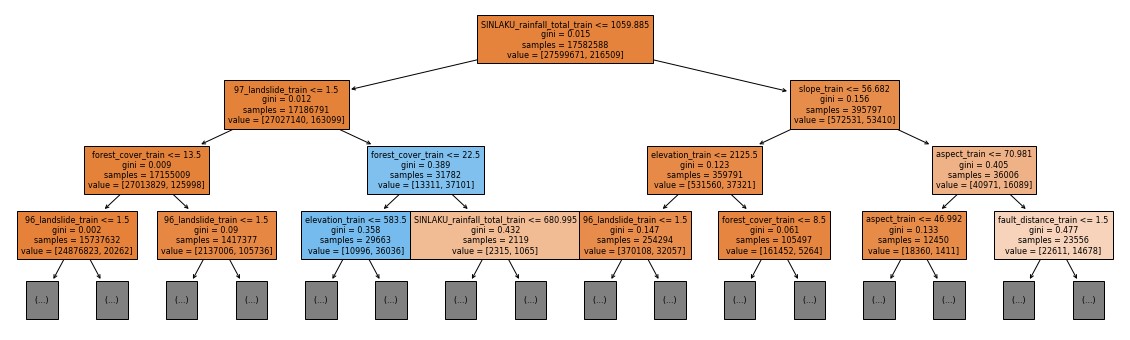
圖1. 決策樹示意圖 (來源:TCCIP計畫產出)
隨機森林(Random Forest)為決策樹之進階版,係由數個決策樹組合成一個集成模型(Ensemble Model)。有學者[2]比較不同演算法對於韓國都會區崩塌潛勢的預測結果,結果顯示隨機森林有較好的預測效果。另有研究[3]則以隨機森林搭配氣候變遷資料預測2050及2092年的崩塌潛勢,並評估森林計畫可帶來的調適效益。
隨機森林通過結合多個決策樹的預測能力來提高整體模型的準確性和穩健性(Robust),能改善單一決策樹模型過度擬合之問題[4],並提升模型預測能力,減少各特徵之間共線性問題,適合運用於影響因素眾多的崩塌問題。因此,本研究選擇使用 40 個決策樹,樹深為 40 的隨機森林模型對臺灣西南部山區(主要為荖濃溪集水區)進行崩塌預測(圖2)。該區域屬高屏溪主流上游,2009年莫拉克颱風期間受到強降雨之影響,荖濃溪眾多支流上游產生大量的崩塌與土石流,2021年0806豪雨造成明霸克陸橋遭沖毀。將整個區域以8:2比例切分為訓練集(training set)與測試集(testing set)[註2],使用訓練集資料建置模型,並在測試集進行崩塌區域預測,最後比較預測區域和實際崩塌區域的差異,藉此評估模型的表現。
隨機森林模型訓練
模型訓練所使用到的特徵包含:高程、坡度、坡向、地表縱向曲率、地表平面曲率、地形濕度指數(TWI)、月均降水、地質圖、斷層距、褶皺距、道路距、河流距、常態化差異建物指標(NDBI)、常態化差異植生指標(NDVI),總共14種特徵,這些特徵都有可能會影響崩塌的發生。例如,坡度陡、距河流近之區域可能較易發生崩塌;在氣候變遷下未來降雨量趨勢也將增加(如月均降水上升),可能造成崩塌災害更加頻繁。在隨機森林中每個決策樹都被訓練以給定特徵條件下預測是否會崩塌,最後每個決策樹都會有「崩塌」與「未崩塌」的預測結果,模型將依照決策樹多數決判斷一個網格是否發生崩塌。本案例將使用2016年之DEM資料,及2014年以前等特徵資料進行訓練(詳見表1),假設地形條件2016年與2014年類似,並用於預測次年度(2015年)之崩塌發生。
表1. 特徵資料來源 (來源:TCCIP計畫產出)
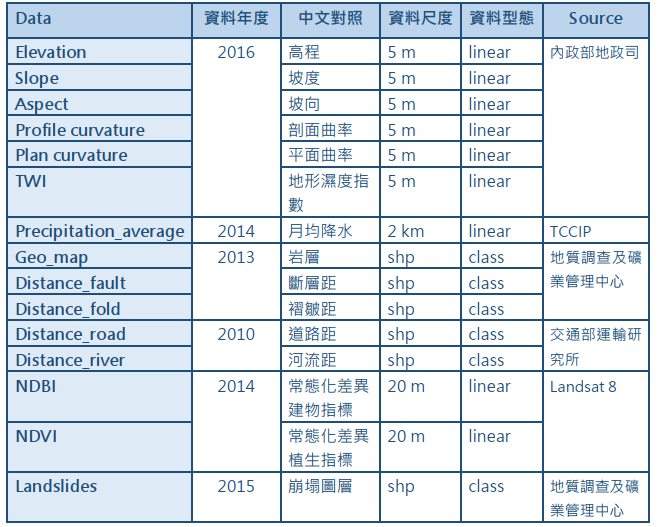

圖2. 機器學習應用區域 (來源:TCCIP計畫產出)

圖3. 應用區域特徵 (來源:TCCIP計畫產出)
模型結果
隨機森林模型訓練完成後,我們可以得到模型在訓練集中的表現(圖4),本例中訓練結果精確率為96.9%,召回率為85.3%[註3]。在訓練集表現良好的模型則能用於測試區域崩塌區域預測,並找出影響崩塌發生的特徵權重,最後評估模型的訓練結果。從模型產出的特徵權重可以告訴我們特徵對崩塌潛勢的解釋力(圖5)。在這個例子中,坡度和坡向對崩塌的預測具有最佳效果。
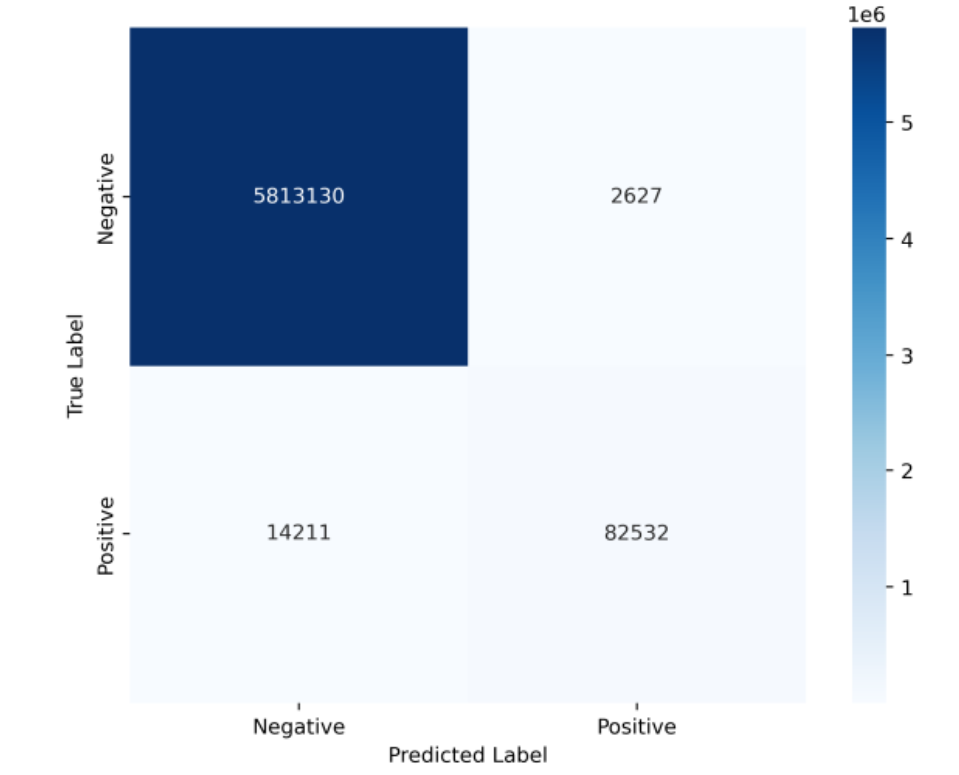
圖4. 隨機森林模型於訓練集表現 (來源:TCCIP計畫產出)
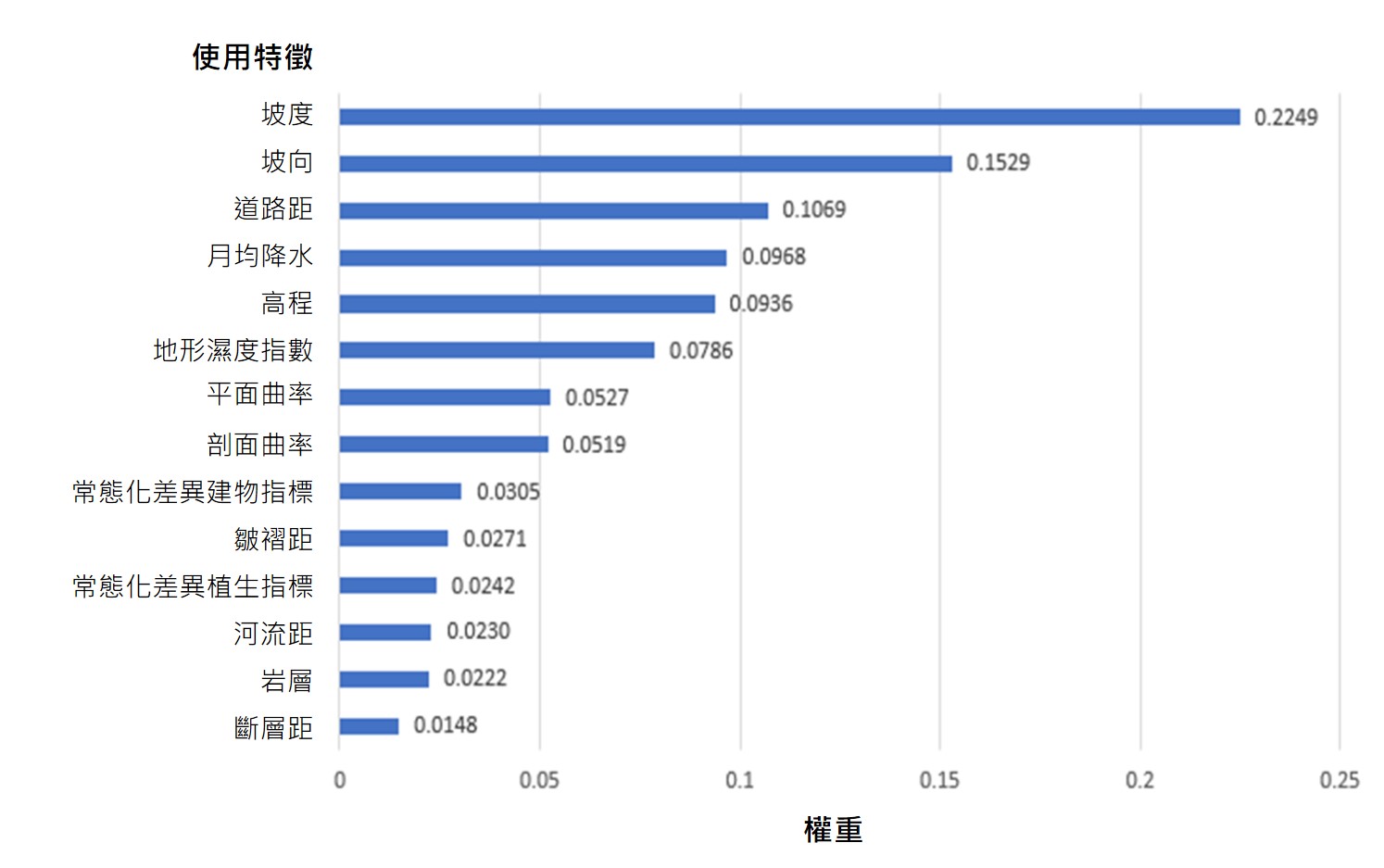
圖5. 特徵權重 (來源:TCCIP計畫產出)
圖6上半部綠框中的藍色斑塊,是隨機森林模型預測的崩塌結果;下半部的紅色斑塊則是實際發生崩塌的位置。從綠框中可以看出隨機森林模型可以預測出大部分崩塌區域的輪廓,在綠框外的區域卻沒有預測出來。如果要更客觀地評估模型的效能,我們會使用混淆矩陣(confusion matrix)[註4]計算模型成功預測出崩塌的比例(圖7),藉此評估隨機森林模型的準確性。
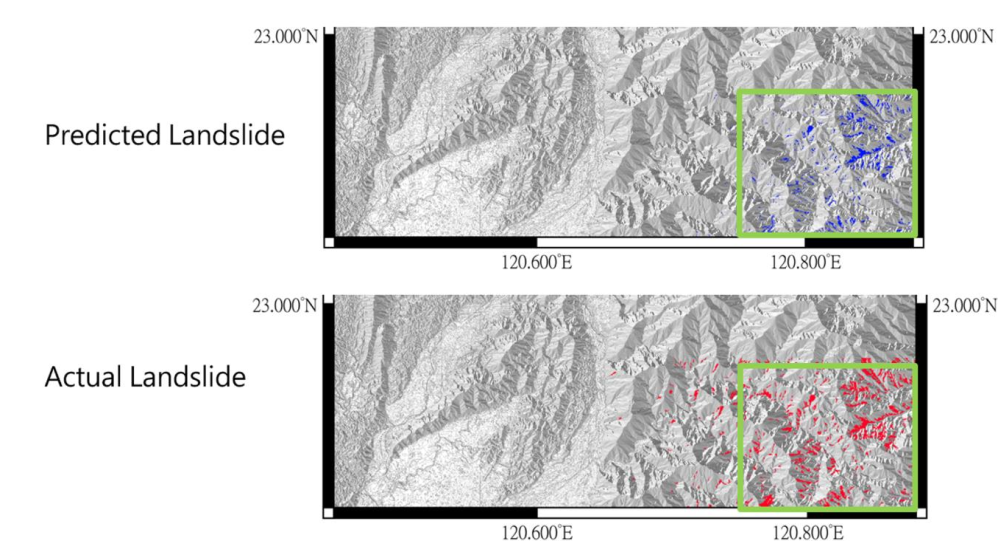
圖6. 隨機森林模擬結果 (來源:TCCIP計畫產出)
圖7為模型在測試集(Test Set)預測結果的混淆矩陣,其中縱軸代表實際的崩塌狀況,橫軸代表模型預測的崩塌狀況,Positive為崩塌,Negative為未崩塌。因為崩塌災害屬於一極端風險,一旦發生將造成非常巨大的負面影響,若模型能夠準確反應出崩塌風險,即使有些許假警訊的產生,都是可以被接受的。因此隨機森林模型的召回率(recall)較高會是理想狀況。這個模型操作下的召回率是 14359 / (14359 + 22749) = 38.7%,意即約有38.7%的崩塌區域成功被模型發現,但仍有61.3%的崩塌事件未成功被發現,改善方法有調整模型參數(增加決策樹的數量或是樹的深度)、增加訓練數據量(引入其他研究認為有效的特徵)、或融合其他模型進行崩塌潛勢評估(例如:LSTM、Transformer等)[5][6]。
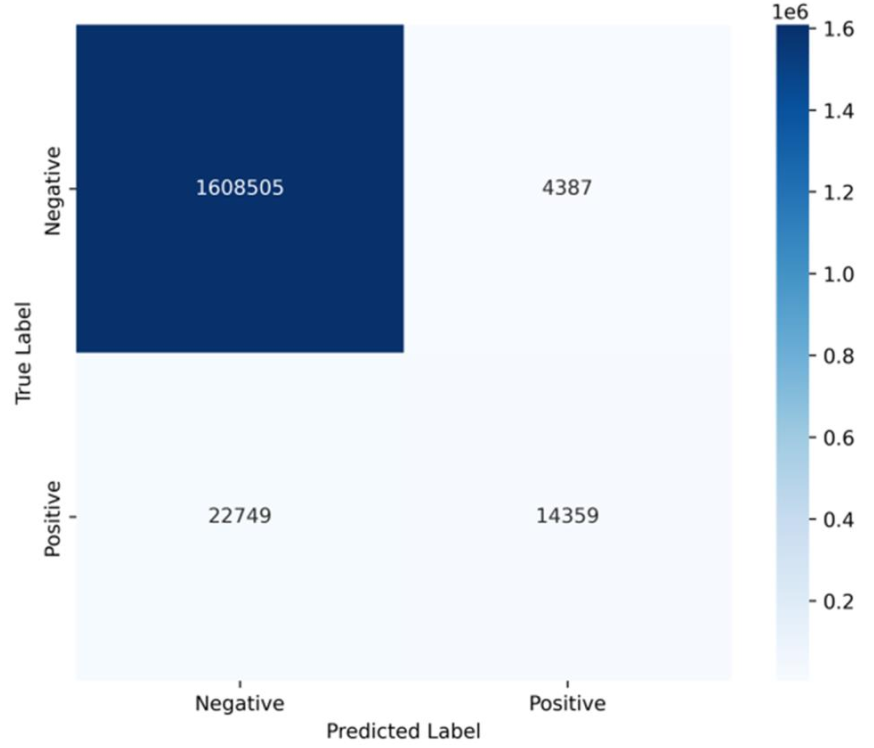
圖7. 混淆矩陣 (來源:TCCIP計畫產出)
總結
機器學習能夠提供更全面及更高效率的分析,可作為氣候變遷崩塌潛勢評估與預測的有力工具。本研究建置之隨機森林模型目前雖未達到最理想的結果,只要透過蒐集其他有效的潛在特徵,或進行每個資料點關聯性的訓練,仍可提供氣候變遷下崩塌災害風險管理參考方向。
延伸閱讀
TCCIP電子報第59期:氣候變遷坡地衝擊評估-以曾文水庫集水區為例
註解
[註1] 特徵與標籤
特徵(feature)是描述樣本的數據,這些數據具備影響崩塌災害發生的可能性因素,是機器學習模型的輸入,用於描述樣本特性,本文中特徵包括高程、坡度、坡向等,這些都是影響崩塌發生可能性的因素。標籤(label)為模型預測目標,描述每個樣本結果,在本文崩塌災害預測的案例中,標籤是二元(Binary)的,即「崩塌」與「未崩塌」,這表示每個樣本都會被分類為這兩種狀態之一。這種分類問題是監督學習(Supervised Learning)的一種,而模型的訓練過程即是使用了特徵和對應的正確標籤。
[註2] 訓練集與測試集
訓練集是用來給模型進行學習的資料,模型的訓練過程即使用訓練集中特徵與對應的正確標籤,找出分類標籤的關鍵特徵。測試集則是用於驗證機器學習模型效能的資料,是機器學習完全沒有學習過的資料,與訓練集資料性質與分佈同,將預測結果與測試集中標籤資料比對,進行訓練成果評估。整個模型訓練到測試過程中如同考試練習,學生先進行題庫的練習(訓練集),在大型考試中(測試集)驗證題庫練習的結果。
[註3] 精確率(precision)與召回率(recall)
精確率與召回率是評估模型性能的指標:
精確率 = 真陽性 / ( 真陽性 + 假陽性 )
召回率 = 真陽性 / ( 真陽性 + 假陰性 )
在本例中召回率代表成功預測出實際崩塌區域的比例。召回率愈高代表有高比例的實際崩塌區域被模型預測成功,而山崩是需要盡量避免的極端風險,因此高的真陽性樣本數(高召回率)是較佳的結果,而較多的假陽性樣本數(低精確率)是相對可被接受的。
[註4] 混淆矩陣
混淆矩陣(Confusion matrix)是用於評估機器學習分類效能的表格,將實際情況與預測結果交叉列出,形成 4 個象限:
真陽性(TP) = 實際崩塌中模型預測崩塌的數量
真陰性(TN) = 實際為未崩塌中模型預測為未崩塌的數量
假陽性(FP) = 實際為未崩塌模型預測崩塌的數量
假陰性(FN) = 實際為崩塌模型預測未崩塌的數量
在本例圖6中縱軸為實際崩塌與實際未崩塌,橫軸為模型預測崩塌與預測未崩塌,混淆矩陣可以幫助我們評估模型的效能,例如準確率(Accuracy)、精確率(Precision)、召回率(Recall)等指標。
.png)
應用機器學習產製臺灣離島1980-2021年氣候資料
楊承道 專案佐理研究員 國家災害防救科技中心
李彥緯 專案助理研究員 國家災害防救科技中心
翁叔平 副教授 國立臺灣師範大學地理學系
前言
氣候變遷研究的首要工作為建立長期氣候資料,以進行統計分析從而瞭解氣候特性,並支持後續的災害風險評估與調適研究等應用。在澎湖、金、馬等離島地區,除了早期由交通部中央氣象署(以下簡稱氣象署)所設置的人工測站擁有長期的觀測資料外,多數自動測站由於成立時間較晚,難以提供足夠長期的觀測資料對離島地區進行全面的氣候分析。臺灣歷史氣候重建資料(Taiwan ReAnalysis Downscaling data,TReAD) 擁有超過40年 (1980-2021年)由模擬所得之歷史重建資料[1]。但模擬得到的TReAD網格資料仍然與實際測站觀測資料有差異,本研究透過機器學習方法修正TReAD的統計特性,使其更接近實際離島測站觀測的氣候特性,可以得到一組既符合測站觀測特性同時又保有長期資料優勢的離島TReAD偏差修正資料,以便離島地區進行長期氣候分析與氣候變遷的衝擊評估。
資料來源
1、測站觀測資料
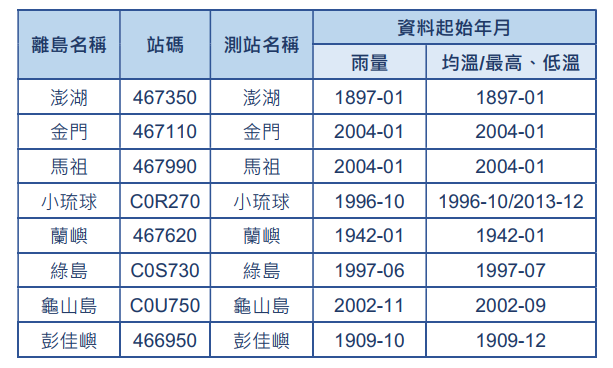
收集的觀測資料包括氣象署設立在臺灣離島地區的人工測站和自動測站資料,涵蓋日降雨、日均溫、日最高溫、日最低溫等變數。根據臺灣各離島的代表測站列表(表1)來看,各測站各變數的資料起始時間,除了氣象署的澎湖站、蘭嶼站和彭佳嶼站等測站外,其它測站的資料起始時間均在1996年以後。
表1. 臺灣各離島的代表測站列表,包含各測站的站碼、測站名稱和不同資料變數的資料起始時間。
(溫度包含日均溫、日最高溫及日最低溫)
2、臺灣歷史氣候重建資料 (Taiwan ReAnalysis Downscaling data,TReAD)
此組資料由國科會「臺灣氣候變遷推估資訊與調適知識平台計畫」團隊提供。利用美國國家大氣研究中心所發展的天氣研究與預報模式 (Weather Research and Forecasting model, WRF),將歐洲中期天氣預報中心 (European Centre for Medium-Range Weather Forecasts, ECMWF) 所產製的重分析資料 (ECMWF Reanalysis v5, ERA5)(ECMWF, 2017) [2],進行動力降尺度,產製出臺灣地區歷史氣候高時空間解析度且多變數之資料。
三、資料產製方法與流程
從TReAD網格資料整理出離島地區鄰近氣象署測站點的網格點資料。觀測資料來自離島地區較具代表性的氣象署人工測站和自動站,臺灣各離島的代表測站列表如表1所示。
TReAD網格點資料的偏差修正方法是採用核密度分布映射(Kernel Density Distribution Mapping, KDDM)法[3] 。KDDM主要目的是將TReAD網格點資料之機率分佈(Probability Density Functions, PDF) 轉換成與歷史測站觀測資料之機率分佈一致 (如圖1所示)。相較於傳統常用的分位數映射法(Quantile Mapping),KDDM 方法無需對資料分佈的形態作出預設假定,且能精確地配適目標分佈,適用於處理更為複雜的資料分佈情況。此外,KDDM 的映射函數(樣條函數估計 ;Spline Fitting)能夠外推至觀測值範圍之外,對極端值的處理更為靈活。
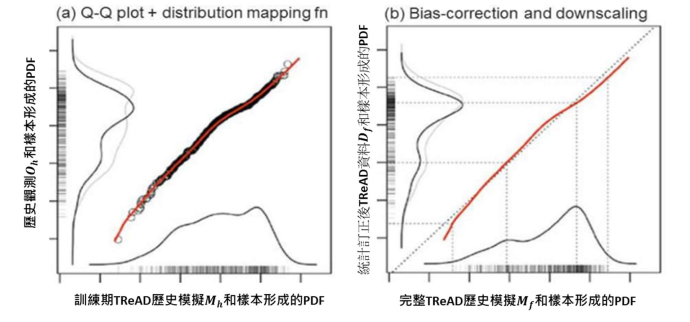
圖1. 圖1a顯示假定的訓練期TReAD歷史摸擬 (X軸) 和測站觀測資料 (Y軸) 的Q-Q plot散點圖,以及特定的映射函數 (紅色曲線) 。圖1b中4條虛線顯示如何應用映射函數進行偏差修正。圖中個別的細黑實線代表其各自的樣本群所形成的機率密度函數 (PDF) 。另外,在X軸顯示TReAD網格資料樣本所形成的PDF再額外鏡射在Y軸上 (細灰實線),以突顯訂正前後造成的改變。圖1b中統計訂正後的TReAD網格點資料應產生和歷史測站觀測樣本有近乎一致的PDF。 (原圖出處:McGinnis et al., 2015) [3]
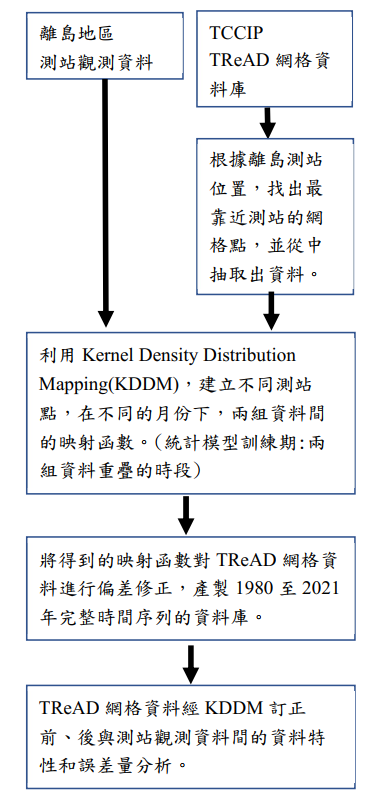
圖2. TReAD離島測站偏差修正資料產製流程圖 (來源:TCCIP計畫產出)
TReAD離島測站點的偏差修正流程如圖2所示。在這項研究中,利用離島地區測站觀測資料和TReAD網格點資料重疊的時段,依各月份進行KDDM統計模型的訓練得到統計模型關係式,並使用映射函數進一步對TReAD網格點資料進行偏差修正,以使修正後的TReAD網格點資料更接近於測站觀測資料。利用相同月份的資料訓練KDDM模型,除了可以保證資料的同質性,提高模型的穩定性外,另外可以更好地捕捉每個月的資料特性和氣候特徵,提高校正精準度。修正的時間範圍為1980~2021年,資料變數包含降雨與溫度之日資料。
四、分析與討論
為評估TReAD在離島地區鄰近測站點的資料經過KDDM方法修正前、後的誤差量改善程度以及資料特性是否接近測站觀測資料,因此計算TReAD網格點資料經KDDM修正前、後與測站觀測料之間的均方根誤差(Root Mean Squared Error,RMSE)以及三組資料重疊時段的資料平均值和標準差。透過這些指標的計算,可以評估KDDM方法對TReAD網格點資料的修正效果以及修正後的資料特性是否接近於測站觀測資料。
表2為TReAD網格資料在離島地區鄰近測站點的雨量資料,經KDDM訂正前、後,各月份的平均值、標準差的總體平均值與測站觀測資料的比較。還有KDDM訂正前、後的資料與測站觀測資之間的各月份均方根誤差的總體平均值。表2顯示除了部分的測站點資料外(紅色數字),經過KDDM訂正的TReAD雨量資料平均值、標準差大都更接近觀測資料。另外,均方根誤差分析顯示除了部分測站點的訂正效果不明顯(紅色數字),其他測站點皆顯示訂正後的雨量資料誤差量比訂正前小。
表3為日均溫的分析結果。各測站點日均溫資料經過KDDM偏差修正後,12個月份的平均值和標準差的總體平均值皆與測站資料相近。均方根誤差的分析結果顯示訂正後的資料誤差量大都比訂正前小。蘭嶼和龜山島站的誤差量甚至可減少約50%,顯示KDDM偏差修正可有效提高資料的準確性和可靠度。同樣地,其它變數包括日最高溫與日最低溫的分析結果皆顯示KDDM有顯著的偏差修正效果。
表2. TReAD在離島地區鄰近測站點的雨量資料,經過KDDM訂正前、後,各月份平均值、標準差的總體平均值與測站觀測資料(OBS)的比較。以及偏差修正前、後,TReAD網格點資料與測站觀測資料之間各月份的均方根誤差(RMSE)總體平均值。(單位:mm/day)
.png)
表3. 同表2,但為日均溫的分析結果。(單位:°C)
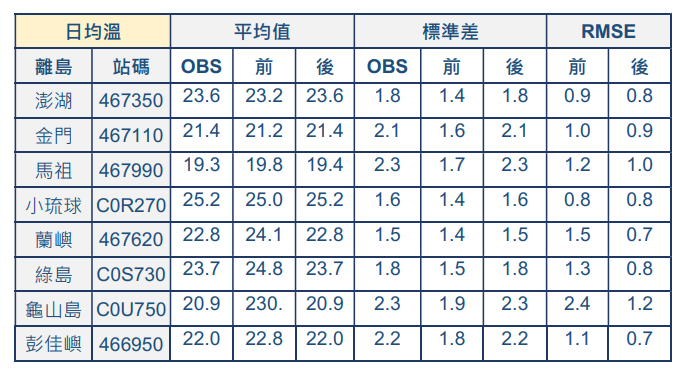
臺灣歷史氣候重建資料TReAD是模式模擬資料,和實際測站觀測資料存在差異,即使經過統計訂正後的TReAD網格點資料之平均值、標準差等資料特性雖與測站觀測資料相近,有助於提高資料的準確性和可靠性,但仍然和測站觀測資料有所不同,無法等同視為實際觀測資料。因此,在使用臺灣離島歷史氣候資料,請需注意以下幾點: (1)當有測站觀測資料可供使用時,應優先採用觀測資料,例如澎湖、蘭嶼和彭佳嶼這些擁有較長觀測歷史的測站;(2)此資料較適合應用於長期氣候分析研究,而非短期氣象分析;(3) 若研究聚焦於極端氣候事件(例如日豪雨),則應謹慎評估此資料的適用性。
目前,臺灣離島歷史氣候資料主要提供降雨及溫度資料。未來將計畫新增日平均風速及日平均相對濕度等變數,以提升離島氣候資料庫的豐富性,進而支持更深入的長期氣候分析與氣候變遷相關研究。
延伸閱讀
TCCIP電子報第46期:歷史觀測資料補遺救星-臺灣歷史氣候重建資料
TCCIP電子報第71期:TCCIP資料服務統計平台優化與調整

氣候模式GCM、ESM之簡介與兩者異同
陳昭安 國家災害防救科技中心 專案助理研究員
趙品諭 國家災害防救科技中心 專案佐理研究員
前言
由過去歷次聯合國政府間氣候變遷專門委員會(Intergovernmental Panel on Climate Change, IPCC)的評估報告,以及臺灣今年發布的國家氣候變遷科學報告2024,顯示過去數十年的氣候變遷科學研究進展,以及從觀測與未來推估的全球暖化趨勢。當我們在閱讀這些評估報告或相關研究文獻時,可以常常看到氣候研究利用各種數值模式做為實驗工具,例如AGCM、GCM、ESM 等等,模擬氣候在過去、現今與未來可能的變遷趨勢。這些縮寫代表不同類型的數值模式,他們的架構與功能又有哪些異同,將在本文介紹說明。
什麼是GCM
GCM 這個英文縮寫一開始指的是環流模式 General Circulation Model[1][2][3],後來也可表示為全球氣候模式 Global Climate Model [3]。General Circulation Model 環流模式將大氣或海洋的三維空間劃分為水平方向與垂直方向的網格結構(如圖1所示),將系統的物理定律轉化為數學方程式,利用數值模式隨著時間積分計算,來描述大氣或海洋系統中的物理過程、流體運動、能量收支平衡的關係,以及系統中不同物理過程或是相鄰網格之間的交互作用(如圖2所示),進而幫助科學家了解氣候系統的運作機制與變化[2]。
Global Climate Model (GCM)全球氣候模式顧名思義是用來模擬全球氣候變化的數值模式,在一個全球氣候模式中通常會考慮大氣、海洋、陸地、冰雪圈等主導全球氣候變化的關鍵因素[3]。無論是環流模式或全球氣候模式,都可以透過不同實驗設定,例如不同溫室氣體排放濃度,協助科學家進行氣候研究,理解氣候系統在不同情境下可能的氣候變化。大氣與海洋環流模式常被使用於氣候研究的氣候模式中,因此,環流模式與全球氣候模式這兩種表達方式通常可交互使用。
GCM又可依據其組成進一步區分表示[3][4][5]:對於僅考慮大氣過程的環流模式稱為大氣模式Atmospheric General Circulation Model,一般縮寫表示為AGCM;僅考慮海洋過程的環流模式則稱為海洋模式Oceanic General Circulation Model,一般縮寫表示為OGCM;同時考慮大氣與海洋過程,以及大氣海洋之間交互作用的環流模式,則稱為海氣耦合模式,以AOGCM(Atmosphere-Ocean General Circulation Model )或CGCM (Coupled General Circulation Model)表示;區域氣候模式 (Regional Climate Models) 簡稱為RCM。
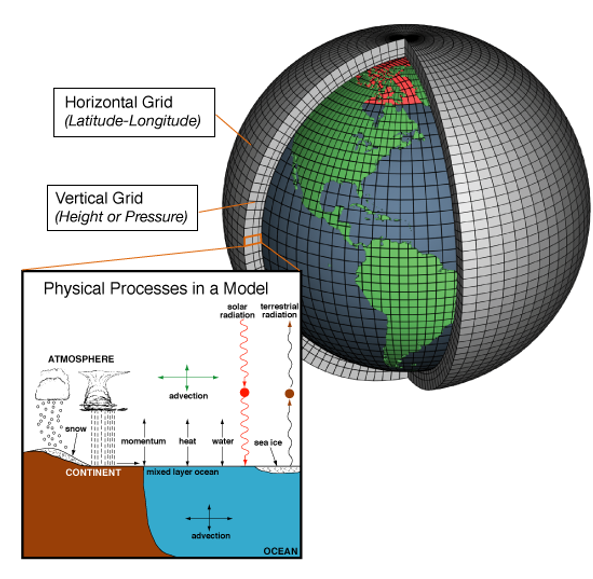
圖1. 氣候模式三維網格示意圖 (來源:參考文獻[6])
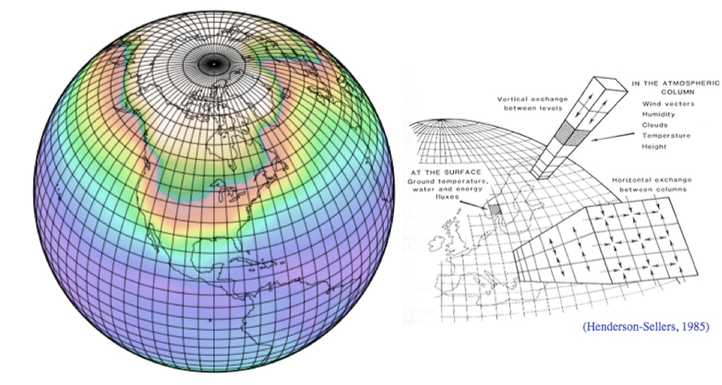
圖2. 模式三維網格與網格點變數計算示意圖 (來源:參考文獻[7] )
什麼是ESM
ESM是地球系統模式Earth System Model的縮寫,地球系統的影響因素除了主要的大氣組成與海洋組成,還包括冰雪圈、陸地、植被生態動力、碳循環、氣膠、甲烷與永凍土、海洋生地化循環、土地利用、大氣化學與氣候交互作用、野火、對流層與平流層交互作用等過程[5],以及人類活動對地球系統影響等因素之交互作用,進而對氣候造成影響(如圖3所示)。在地球系統模式的氣候變遷模擬實驗中,不僅可呈現溫室氣體濃度改變對大氣、海洋的溫度、降雨與環流等變化之影響,也可以表現暖化氣候對植被、碳循環、其他生地化過程與生態系統之作用,以及這些過程又如何進一步與其他地球系統組成的交互作用。因此,ESM模式的架構與運作更接近真實地球且完整,能夠更接近真實地模擬長期氣候變化的潛在影響,在氣候變遷研究與應用,能夠提供更全面與詳細的資訊,但也因此在模擬運算過程更為複雜。
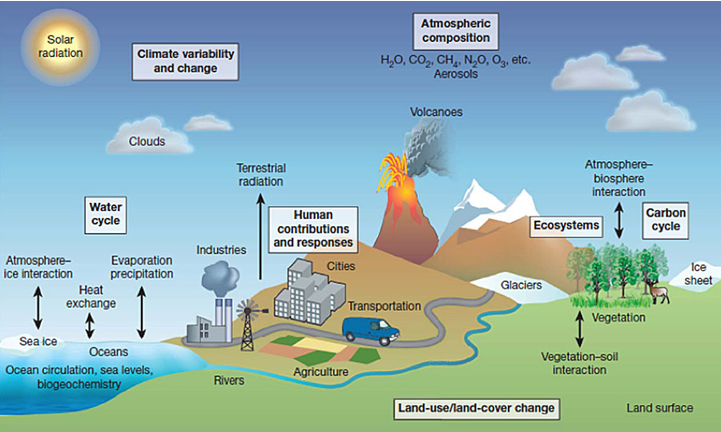
圖3. 地球系統模式中,主要的自然與人為過程示意圖。(來源:參考文獻[8])
GCM與ESM的相同之處
氣候變遷科學議題對於氣候系統的理解與探索更為深入,以及氣候模式發展技術演進,也反映在GCM與ESM的模式發展。氣候模式最初的形式還並未考慮三維的空間結構,僅是由簡單的數學方程式計算,來表示大氣中的基本熱力學與動力學物理過程運作。在20世紀中期,隨著電腦運算技術的進步,科學家們能夠將三維空間的流體的物理過程與能量收支平衡關係建立在GCM中(參考網站1),這些模式能夠模擬大氣和海洋的環流,以及它們如何隨時間變化,使得GCM 能夠重現全球尺度的氣候運作,並且成為研究全球氣候變遷的重要工具。因此,從模式發展的歷程來看,GCM 可以說是 ESM 的前身,代表了地球系統模式建立的基礎階段。隨著科學和技術的進步,ESM 在 GCM 的架構之上進行組成擴增與改進[5],進而能夠更全面的重現氣候系統的變化與反饋過程,成為能夠模擬更複雜的地球系統相互作用的工具。
因此,就基本架構上,GCM和 ESM都是能夠用來模擬和推估地球氣候系統的數值模式。GCM與ESM皆將地球的三維空間以網格化表示,兩者皆透過流體的物理定律與動力過程,以數學方程式計算格點上與彼此之間的變數變量。隨著數值模式的時間積分,呈現出地球氣候系統隨時間的演進與變化。在當中的物理過程,兩者都可模擬地球系統中的大氣組成與海洋組成;例如在大氣組成的部分可表現對流活動、大尺度環流運動、輻射傳輸與大氣層內的能量收支平衡;而海洋組成的部分,可模擬洋流、溫鹽環流以及海洋內部的能量收支平衡與傳輸。GCM與ESM皆廣泛被使用於研究氣候變化,因此兩者皆可透過實驗情境設定,例如不同程度的溫室氣體排放,進行數十年甚至上百年時間尺度的氣候模擬,來估算未來氣候系統可能的變化趨勢,在氣候研究中扮演關鍵角色。簡而言之,GCM 和 ESM 的共通之處在於它們都用來模擬地球氣候系統的物理過程,並且都在氣候變化研究中發揮了重要作用。
GCM與ESM的相異之處
GCM主要考慮大氣與海洋的動力與熱力過程,可模擬氣候系統中的溫度變化、季風演進、熱帶氣旋、海洋環流、海洋溫度與鹽度的垂直結構分布等等,考慮較單純的氣候系統變化。而ESM除了前述GCM的功能之外,還考慮了地球氣候系統其他組成的運作,例如:碳循環、海洋與陸地的生物地質化學過程、大氣化學過程、人為作用、土地利用改變、森林砍伐等等,因此能透過模式模擬,對於氣候變遷情境如何影響大氣與碳循環的交互作用、植物生長、海洋酸化等議題,以及這些組成的變化如何回饋氣候系統,能夠以更貼近真實世界運作,預測長期的氣候變化和對生態、人類社會經濟的綜合影響。這些資訊無法由單純只考慮大氣與海洋組成的GCM推得。
過去為了拓展對氣候變遷研究之理解、推估未來氣候的可能發展,與評估氣候變遷帶來的潛在風險與衝擊,科學家需要能夠模擬地球氣候系統中複雜交互作用的研究工具,這樣的需求持續推動了環流模式、氣候模式以及後來的地球系統模式發展。IPCC第六次評估報告指出,人為活動導致溫室氣體增加,進而影響全球暖化與氣候變遷,在氣候研究上的證據越來越充分。暖化帶來的氣候變遷對生態系統、經濟和社會的廣泛影響,是當今全球共同面臨的嚴峻挑戰。藉由GCM與ESM幫助我們對於未來氣候的各種可能情境進行更深入的理解,提供更細緻的推估資訊以建立風險衝擊評估。
參考文獻
主題一文獻
[1] Quinlan, J. R., 1986. Induction of decision trees. Machine learning, 1(1), 81-106.
[2] Park, S. J., and Lee, D. K., 2021. Predicting susceptibility to landslides under climate change impacts in metropolitan areas of South Korea using machine learning. Geomatics, Natural Hazards and Risk, 12(1), 2462-2476.
[3] Lim, Chul-Hee, and Hyun-Jun Kim, 2022. "Can Forest-Related Adaptive Capacity Reduce Landslide Risk Attributable to Climate Change?—Case of Republic of Korea" Forests 13, no. 1: 49.
[4] Breiman, L. Random Forests., 2001. Machine Learning 45, 5–32. https://doi.org/10.1023/A:1010933404324.
[5] Armin Moghimi, Chiranjit Singha, Mahdiyeh Fathi, Saied Pirasteh, Ali Mohammadzadeh, Masood Varshosaz, Jian Huang, Huxiong Li, 2024. Hybridizing genetic random forest and self-attention based CNN-LSTM algorithms for landslide susceptibility mapping in Darjiling and Kurseong, India, Quaternary Science Advances, Volume 14, 100187, ISSN 2666-0334, https://doi.org/10.1016/j.qsa.2024.100187.
[6] Zhou, Y., Hussain, M. A., & Chen, Z., 2023. Landslide susceptibility mapping with feature fusion transformer and machine learning classifiers incorporating displacement velocity along Karakoram highway. Geocarto International, 38(1). https://doi.org/10.1080/10106049.2023.2292752
返回主題一
主題二文獻
[1] 林秉毅、鄭兆尊,2021年3月。TCCIP電子報第46期:歷史觀測資料補遺救星-臺灣歷史氣候重建資料。臺灣氣候變遷推估資訊與調適知識平台。 https://tccip.ncdr.nat.gov.tw/km_newsletter_one.aspx?nid=20210323110413
[2] European Centre for Medium-Range Weather Forecasts, 2017, updated monthly. ERA5 Reanalysis. Research Data Archive at the National Center for Atmospheric Research, Computational and Information Systems Laboratory. https://doi.org/10.5065/D6X34W69.
[3] McGinnis S, Nychka D, Mearns L., 2015: A new distribution mapping technique for climate model bias correction. In: Lakshmanan, V., Gilleland, E., McGovern, A. and Tingley, M. (Eds.) Machine Learning and Data Mining Approaches to Climate Science. Cham: Springer. https://doi.org/10.1007/978-3-319-17220-0_9.
返回主題二
主題三文獻
[1] Houghton, J. T. (Ed.). (1996). Climate change 1995: The science of climate change: contribution of working group I to the second assessment report of the Intergovernmental Panel on Climate Change (Vol. 2). Cambridge University Press.
[2] McAvaney, B.J., et al. 2001: Model Evaluation. In: Climate Change 2001: The Scientific Basis. Contribution of Working Group I to the Third Assessment Report of the Intergovernmental Panel on Climate Change [Houghton, J.T., Y. Ding, D.J. Griggs, M. Noguer, P.J. van der Linden, X. Dai, K. Maskell, and C.A. Johnson (eds.)]. Cambridge University Press, Cambridge, United Kingdom and New York, NY, USA, 881pp. https://www.ipcc.ch/site/assets/uploads/2018/03/TAR-08.pdf
[3] Albritton, D.L., et al. 2001: Technical Summary. In: Climate Change 2001: The Scientific Basis. Contribution of Working Group I to the Third Assessment Report of the Intergovernmental Panel on Climate Change [Houghton, J.T., Y. Ding, D.J. Griggs, M. Noguer, P.J. van der Linden, X. Dai, K. Maskell, and C.A. Johnson (eds.)]. Cambridge University Press, Cambridge, United Kingdom and New York, NY, USA, 881pp. https://www.ipcc.ch/site/assets/uploads/2018/07/WG1_TAR_TS.pdf
[4] Baede, A.P.M., et al. 2001: The Climate System: an Overview. In: Climate Change 2001: The Scientific Basis. Contribution of Working Group I to the Third Assessment Report of the Intergovernmental Panel on Climate Change [Houghton, J.T., Y. Ding, D.J. Griggs, M. Noguer, P.J. van der Linden, X. Dai, K. Maskell, and C.A. Johnson (eds.)]. Cambridge University Press, Cambridge, United Kingdom and New York, NY, USA, 881pp. https://www.ipcc.ch/site/assets/uploads/2018/03/TAR-01.pdf
[5] Flato, G., J. Marotzke, B. Abiodun, P. Braconnot, S.C. Chou, W. Collins, P. Cox, F. Driouech, S. Emori, V. Eyring, C. Forest, P. Gleckler, E. Guilyardi, C. Jakob, V. Kattsov, C. Reason and M. Rummukainen, 2013: Evaluation of Climate Models. In: Climate Change 2013: The Physical Science Basis. Contribution of Working Group I to the Fifth Assess ment Report of the Intergovernmental Panel on Climate Change [Stocker, T.F., D. Qin, G.-K. Plattner, M. Tignor, S.K. Allen, J. Boschung, A. Nauels, Y. Xia, V. Bex and P.M. Midgley (eds.)]. Cambridge University Press, Cambridge, United Kingdom and New York, NY, USA
[6] Top Ten Breakthroughs of NOAA 200 Years Celebration: The First Climate Model, from https://celebrating200years.noaa.gov/breakthroughs/climate_model/welcome.html#model
[7] NASA Center for Climate Simulation, Creating the Models, from https://www.nccs.nasa.gov/services/climate-data-services
[8] Background of GFDL Earth System Models, from https://www.gfdl.noaa.gov/earth-system-model/
返回主題三
喜歡這一期的文章嗎? 給作者一個讚!